[iOS]画像解析フレームワークVision Framework入門
# Vision Frameworkとは? Vision FrameworkはAppleが提供する、コンピュータービジョン技術を簡単に扱えるフレームワークです。 2017年のWWDCで発表されました。iOS 11.0以上、macOS 10.13以上で利用できます。 コンピュータービジョン技術に精通していなくても物体認識をできるフレームワークです。

![[iOS]画像解析フレームワークVision Framework入門](/content/images/size/w2000/2020/05/detect.png)

Vision Frameworkとは?
Vision FrameworkはAppleが提供する、コンピュータービジョン技術を簡単に扱えるフレームワークです。
2017年のWWDCで発表されました。iOS 11.0以上、macOS 10.13以上で利用できます。
コンピュータービジョン技術に精通していなくても物体認識をできるフレームワークです。
組み込みで検知できるものもありますが、Core MLと組み合わせることで独自の物体認識をすることもできます。
アリゴリズムのベースに機械学習が取り入れられているそうです。
Vision Frameworkが検知できるもの
Visionが登場したWWDC 2017のビデオを抜粋します。
Vision Framework: Building on Core ML - WWDC 2017 - Videos - Apple Developer
Vision Frameworkは顔認識を精度高く行うことができます。
例えば最大16人の顔認識を一度にすることができます。

顔の大きさが小さくても検知ができます。

横向きの顔でも、

顔の一部が隠れていても、メガネをかけていても「顔」と認識できます。


また眉毛や目、鼻、口といった顔の特徴点も検知が可能です。

顔認識が今までもCIDetectorがありましたがこれはCore Imageをベースに作られているものです。Vision Frameworkは機械学習をベースに作り直したものだそうです。
Visionができることがまだあります。2つ以上の画像を一つの画像として作成する「Image Registration」があります。パノラマ写真を作ることができます。

矩形の検知や、

バーコードの検知、

文字認識をすることができます。

一文字ずつ矩形で検知できるので、機械学習で文字を判別してテキストに起こすというのが簡単にできそうですね。
あとはオブジェクトトラッキングができます。動画中の物体を追うことができます。

Core MLと組み合わせれば独自のモデルを認識させることも可能だそうです。
デバイスで実行するか?クラウド上で実行するか?
Vision Frameworkはデバイス上で実行されます。
現在ではコンピュータービジョン技術はGoogleやAmazon、Microsoftがクラウドサービスとして提供しています。
ならばこれらのサービスを使えばいいかもしれませんが、AppleはVision Frameworkを使うことでデバイス上で実行する利点を説明しています。
- プライバシーの保護:画像を他のサーバーに送る必要がありません
- 利用料金がかからない
- データ転送の必要なし
- レイテンシーがなく素早く実行できる
他の顔認証技術について
Vision Frameworkが登場する前にもCore ImageやAV Captureにて顔認証ができました。
その性能比較がこちらです。
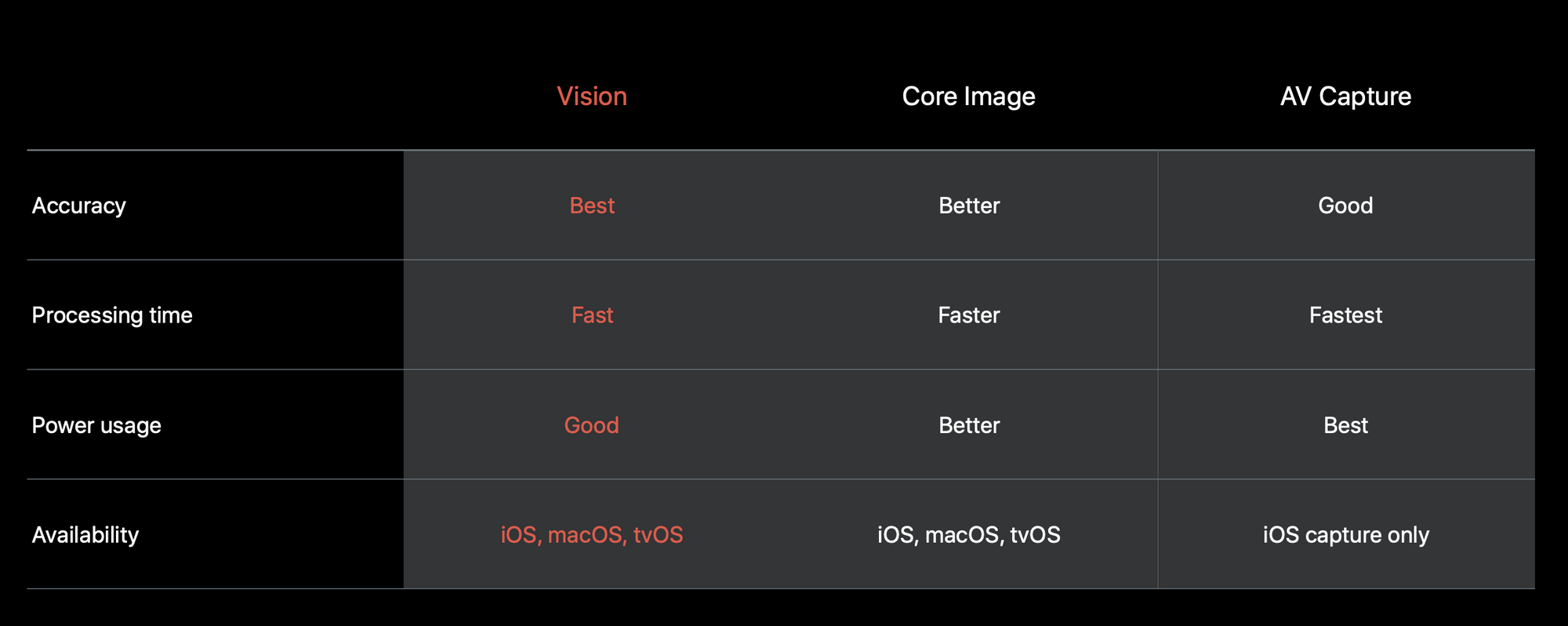
Visionの利点はiOS, macOS, tvOSと様々なプラットフォームで使える正確性が一番よいもののようです。
CIDetectorなどでCore Imageでも顔認識は現状できますが、Vision Frameworkは更にアリゴリズムを改善していくとのことです。
なので、これから顔認識を実装していく場合はVision Frameworkを使ったほうがよさそうです。
Appleのサンプルコード
AppleはiOS向けのVision Frameworkのサンプルコードを提供しています。
今回はこのサンプルコードをもとにVision Frameworkの実装の流れを解説したいと思います。
Detecting Objects in Still Images | Apple Developer Documentation
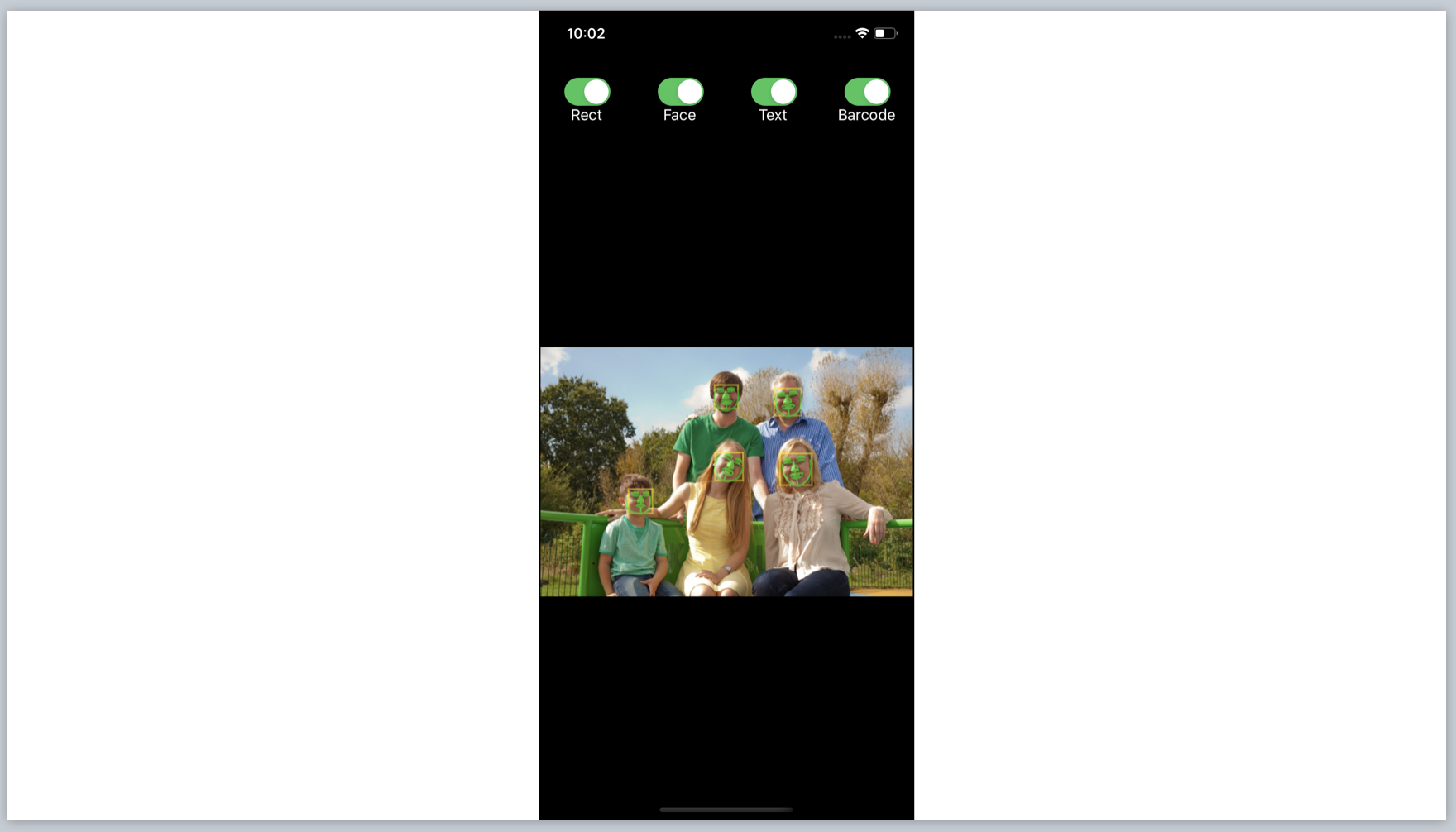
サンプルコードでは画面上部に物体認識する種類をオンオフするトグルスイッチがあります。カメラやフォトライブラリーから画像を読み込むとオンにした種類をVision Frameworkが検知し、Viewにレイヤーを追加する仕組みです。
- Rect: 矩形を検知する
- Face: 画像認識をする。顔の矩形と顔のパーツを検知する
- Text: 文字認識する。人まとまりの文字列の矩形と一文字ずつの矩形を検知する
- Barcode: バーコードを検知する
Visionを使う流れ
リクエストインスタンスを作って、リクエストハンドラーを呼び出します。検知結果がObservationsインスタンスに返ってくるのでそこから矩形情報を扱う流れになるようです。

Reqests
読み込まれた画像からどんな物体を分析するかによってリクエストクラスが別れています。
- VNRecognizeTextRequest: テキストを検知するリクエスト
- VNDetectRectanglesRequest: 長方形の矩形を検知するリクエスト
- VNDetectFaceRectanglesRequest: 顔の矩形を検知するリクエスト
- VNDetectFaceLandmarksRequest: 口や目、鼻などの顔の特徴を検知するリクエスト
- VNDetectBarcodesRequest: バーコードを検知するリクエスト
- QRコードを始め、様々なバーコードの種類を検知できます。詳しくはVNBarcodeSymbologyを見てください
サンプルコードではこのような実装がされていました。
矩形を検知するリクエストのプロパティを作っています。
lazy var rectangleDetectionRequest: VNDetectRectanglesRequest = {
let rectDetectRequest = VNDetectRectanglesRequest(completionHandler: self.handleDetectedRectangles)
// Customize & configure the request to detect only certain rectangles.
rectDetectRequest.maximumObservations = 8 // Vision currently supports up to 16.
rectDetectRequest.minimumConfidence = 0.6 // Be confident.
rectDetectRequest.minimumAspectRatio = 0.3 // height / width
return rectDetectRequest
}()
maximumObservationsで最大検知数を設定しています。
minimumConfidenceで最低信頼度の設定をしています。Vision Frameworkは分析の信頼度がこれよりも低く検知した矩形を結果には反映しないようにします。
minimumAspectRatioで検知した矩形の最小アスペクト比を設定します。
VNDetectRectanglesRequest(completionHandler: self.handleDetectedRectangles)で実行結果のハンドラーを渡しています。
ハンドラーはこのような実装です。
fileprivate func handleDetectedRectangles(request: VNRequest?, error: Error?) {
if let nsError = error as NSError? {
self.presentAlert("Rectangle Detection Error", error: nsError)
return
}
// Since handlers are executing on a background thread, explicitly send draw calls to the main thread.
DispatchQueue.main.async {
guard let drawLayer = self.pathLayer,
let results = request?.results as? [VNRectangleObservation] else {
return
}
self.draw(rectangles: results, onImageWithBounds: drawLayer.bounds)
drawLayer.setNeedsDisplay()
}
}
VNRequestのresultプロパティに検知した矩形情報が入っています。それをもとにViewにレイヤーを追加する流れになっています。
RequestHandlerの実行
Requestsを作ったら続いて、VNImageRequestHandlerを分析する画像をもとに作成します。
VNImageRequestHandlerのperformメソッドにリクエストを渡して実行します。
fileprivate func performVisionRequest(image: CGImage, orientation: CGImagePropertyOrientation) {
// Fetch desired requests based on switch status.
let requests = createVisionRequests()
// Create a request handler.
let imageRequestHandler = VNImageRequestHandler(cgImage: image,
orientation: orientation,
options: [:])
// Send the requests to the request handler.
DispatchQueue.global(qos: .userInitiated).async {
do {
try imageRequestHandler.perform(requests)
} catch let error as NSError {
print("Failed to perform image request: \(error)")
self.presentAlert("Image Request Failed", error: error)
return
}
}
}
try imageRequestHandler.perform(requests)で実行したあと、無事にVision Frameworkが物体検知をすればRequest作成時のcompletionHandlerが呼ばれる仕組みです。
先程の例ではVNDetectRectanglesRequest(completionHandler: self.handleDetectedRectangles)の部分が実行されます。
画像の向きの確認
Vision Frameworkは渡された画像は上向きとみなして分析をするので画像の方向を正しく指定しなければいけません。
VNImageRequestHandlerに渡せる画像の種類は以下の5つです。
- CGImage: コアグラフィックイメージのフォーマットでUIImageから取得できます。イニシャライザの
CGImagePropertyOrientationを通して画像の向きを指定できます - CIImage: コアイメージフォーマット。
CIImageには向きの情報がないのでイニシャライザのinit(ciImage:orientation:options:)で向きの情報を渡す必要があります。 - CVPixelBuffer: コアビデオイメージフォーマットで動画を扱うときに利用します。
CVPixelBufferは向きの情報を含まないのでイニシャライザinit(cvPixelBuffer:orientation:options:)で向き情報を渡す必要があります。 - NSData: ネットワークを通して画像をダウンロードする場合などに使えます。ダウンロードした画像の向きが上向きになっているか確認が必要です。そうでない場合、
init(data:orientation:options:)を使って向き情報を渡す必要があります。 - NSURL: デバイス上の画像URLを使うときに利用できます。
そして画像の向きを正しく設定する実装はサンプルコードのscaleAndOrientメソッドで実装されていました。
イメージピッカーで取得したUIImageを640のサイズに縮小し正しい向きに再設定して画像を縮小する処理です。
func scaleAndOrient(image: UIImage) -> UIImage {
// Set a default value for limiting image size.
let maxResolution: CGFloat = 640
guard let cgImage = image.cgImage else {
print("UIImage has no CGImage backing it!")
return image
}
// Compute parameters for transform.
let width = CGFloat(cgImage.width)
let height = CGFloat(cgImage.height)
var transform = CGAffineTransform.identity
var bounds = CGRect(x: 0, y: 0, width: width, height: height)
if width > maxResolution ||
height > maxResolution {
let ratio = width / height
if width > height {
bounds.size.width = maxResolution
bounds.size.height = round(maxResolution / ratio)
} else {
bounds.size.width = round(maxResolution * ratio)
bounds.size.height = maxResolution
}
}
let scaleRatio = bounds.size.width / width
let orientation = image.imageOrientation
switch orientation {
case .up:
transform = .identity
case .down:
transform = CGAffineTransform(translationX: width, y: height).rotated(by: .pi)
case .left:
let boundsHeight = bounds.size.height
bounds.size.height = bounds.size.width
bounds.size.width = boundsHeight
transform = CGAffineTransform(translationX: 0, y: width).rotated(by: 3.0 * .pi / 2.0)
case .right:
let boundsHeight = bounds.size.height
bounds.size.height = bounds.size.width
bounds.size.width = boundsHeight
transform = CGAffineTransform(translationX: height, y: 0).rotated(by: .pi / 2.0)
case .upMirrored:
transform = CGAffineTransform(translationX: width, y: 0).scaledBy(x: -1, y: 1)
case .downMirrored:
transform = CGAffineTransform(translationX: 0, y: height).scaledBy(x: 1, y: -1)
case .leftMirrored:
let boundsHeight = bounds.size.height
bounds.size.height = bounds.size.width
bounds.size.width = boundsHeight
transform = CGAffineTransform(translationX: height, y: width).scaledBy(x: -1, y: 1).rotated(by: 3.0 * .pi / 2.0)
case .rightMirrored:
let boundsHeight = bounds.size.height
bounds.size.height = bounds.size.width
bounds.size.width = boundsHeight
transform = CGAffineTransform(scaleX: -1, y: 1).rotated(by: .pi / 2.0)
}
return UIGraphicsImageRenderer(size: bounds.size).image { rendererContext in
let context = rendererContext.cgContext
if orientation == .right || orientation == .left {
context.scaleBy(x: -scaleRatio, y: scaleRatio)
context.translateBy(x: -height, y: 0)
} else {
context.scaleBy(x: scaleRatio, y: -scaleRatio)
context.translateBy(x: 0, y: -height)
}
context.concatenate(transform)
context.draw(cgImage, in: CGRect(x: 0, y: 0, width: width, height: height))
}
}
コードを読んでの感想
Detecting Objects in Still Imagesでは画像を取り込んで、Visionが物体認識をしてその矩形を取得しViewにレイヤーとして貼り付ける仕組みが実装されていました。
顔の矩形を検知できればCore MLで作ったモデルに放り込んで「その人は〇〇さん」というような判定が簡単にできそうです。
実際@kenmazさんがQiitaでももクロ顔識別アプリを作っていいました。
Keras + iOS11 CoreML + Vision Framework による、ももクロ顔識別アプリの開発 - Qiita
ただVision Frameworkの結果はBounds情報だけなのでしょうか?
例えばCIDetectorでは物体認識の結果を表すCIFaceFeatureクラスでは笑顔かどうかを表すhasSmileプロパティがあってその顔が笑顔か簡単にわかります。
CIFaceFeature - Core Image | Apple Developer Documentation
Vision Frameworkではその顔がどういう表情になっているのかを扱うにはすべてCore MLを通さないと判断できないんでしょうか?
CIDetectorみたいに簡単にどんな表情なのかを扱う方法はないんでしょうか?
顔認証の表情の扱いについてはもう少し調べていきたいと思います。
参考文献
- Detecting Objects in Still Images | Apple Developer Documentation
- Vision Framework: Building on Core ML - WWDC 2017 - Videos - Apple Developer
- [iOS 11] 画像解析フレームワークVisionで顔認識を試した結果 | Developers.IO
acworksさんによる写真ACからの写真 https://www.photo-ac.com/main/detail/194668?title=公園の三世代家族2
宣伝
インプレスR&D社より、「1人でアプリを作る人を支えるSwiftUI開発レシピ」発売中です。
「SwiftUIでアプリを作る!」をコンセプトにSwiftUI自体の解説とそれを組み合わせた豊富なサンプルアプリでどんな風にアプリ実装すればいいかが理解できる本となっています。
iOS 14対応、Widgetの作成も一章まるまるハンズオンで解説しています。
SwiftUIを学びたい方、ぜひこちらのリンクをチェックしてください!
